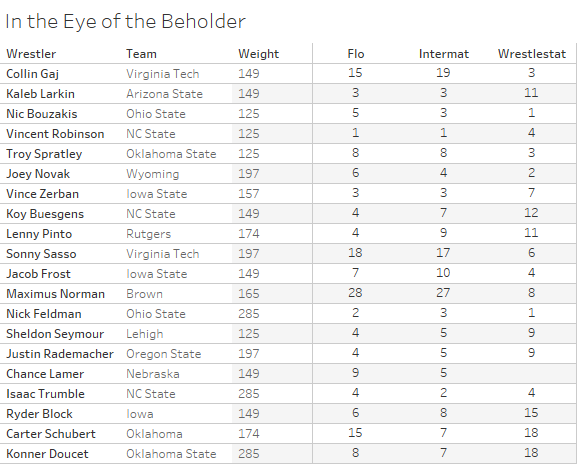
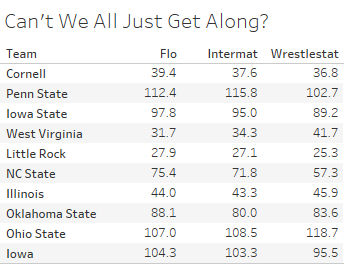
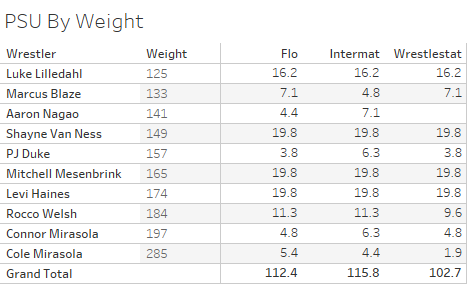
If the brightest minds of the wrestling community could come up with an industry standard for how to properly weight wins/losses/SOS/"ducks"/INJ DEF/tourney places etc. to come up with a quality point system - rankings would take 3 seconds after each weeks matches were entered. I get Britt's(SHP) weekly updates with match results, this is imported into Python Code (sample below) and spits out rankings.
Code can be manipulated to match a quality point system, this would take out the BIAS element. I'm all ears for input on how to set the criteria.
# How much to trust human rankings vs model
# 1.0 = only human, 0.0 = only model
PRIOR_WEIGHT = 0.6
# -----------------------------
# Helpers
# -----------------------------
def parse_result_type(score: str):
"""Map Score string -> result type code: D, M, T, F."""
if not isinstance(score, str):
return None
s = score.strip()
if s.startswith("D;"):
return "D"
if s.startswith("M;"):
return "M"
if s.startswith("T;"):
return "T"
if s.startswith("F;"):
return "F"
if s.lower().startswith("forfeit"):
return "F" # treat forfeit as fall
return None
#Decision MajDec Tech Fall
WIN_QUALITY_MAP = {
"D": 0.60,
"M": 0.75,
"T": 0.90,
"F": 1.00,
}
def normalize(series: pd.Series) -> pd.Series:
"""Normalize a pandas Series to 0–1. If constant, return 0.5."""
if series.empty:
return series
mn = series.min()
mx = series.max()
if mx == mn:
return pd.Series([0.5] * len(series), index=series.index)
return (series - mn) / (mx - mn)
# -----------------------------
# Core ranking logic per weight
# -----------------------------
def compute_rankings_for_weight(df_weight: pd.DataFrame) -> pd.DataFrame:
"""
Compute rankings for a single weight class based only on match data.
Returns a DataFrame with columns:
Wrestler, Matches, Wins, Losses, WinPct,
WQS, BR, OSS, QLS, RS,
WQS_n, BR_n, OSS_n, QLS_n, RS_n, Score
"""
records = {}
def ensure_wrestler(name: str):
if name not in records:
records[name] = {
"matches": 0,
"wins": 0,
"losses": 0,
"bonus_wins": 0,
"win_quality_sum": 0.0,
"dates": [],
"results_by_date": [], # list of (date, is_win)
}
# 1) First pass: basic stats
for _, row in df_weight.iterrows():
date = row["Date"]
try:
date = pd.to_datetime(date)
except Exception:
date = pd.NaT
w_name = str(row["Winning Wrestler"]).strip()
l_name = str(row["Losing Wrestler"]).strip()
rtype = row.get("ResultType", None)
ensure_wrestler(w_name)
ensure_wrestler(l_name)
# Winner
rec_w = records[w_name]
rec_w["matches"] += 1
rec_w["wins"] += 1
rec_w["dates"].append(date)
rec_w["results_by_date"].append((date, 1))
if rtype in WIN_QUALITY_MAP:
q = WIN_QUALITY_MAP[rtype]
rec_w["win_quality_sum"] += q
if rtype in ["M", "T", "F"]:
rec_w["bonus_wins"] += 1
# Loser
rec_l = records[l_name]
rec_l["matches"] += 1
rec_l["losses"] += 1
rec_l["dates"].append(date)
rec_l["results_by_date"].append((date, 0))
# 2) Win% per wrestler
for name, rec in records.items():
m = rec["matches"]
w = rec["wins"]
rec["win_pct"] = w / m if m > 0 else 0.0
winpct = {name: rec["win_pct"] for name, rec in records.items()}
# 3) Initialize opponent stats
for name in records:
records[name]["opp_winpct_sum"] = 0.0
records[name]["opp_count"] = 0
records[name]["loss_quality_sum"] = 0.0
records[name]["loss_count"] = 0
# 4) Second pass: opponent strength & quality losses
for _, row in df_weight.iterrows():
w_name = str(row["Winning Wrestler"]).strip()
l_name = str(row["Losing Wrestler"]).strip()
# Winner sees loser as opponent
records[w_name]["opp_winpct_sum"] += winpct.get(l_name, 0.0)
records[w_name]["opp_count"] += 1
# Loser sees winner as opponent
records[l_name]["opp_winpct_sum"] += winpct.get(w_name, 0.0)
records[l_name]["opp_count"] += 1
# Quality loss for loser
opp_wp = winpct.get(w_name, 0.0)
records[l_name]["loss_quality_sum"] += opp_wp
records[l_name]["loss_count"] += 1
# 5) Build metric dataframe
rows = []
for name, rec in records.items():
m = rec["matches"]
if m == 0:
continue
wins = rec["wins"]
losses = rec["losses"]
win_pct = rec["win_pct"]
bonus_wins = rec["bonus_wins"]
if wins > 0 and rec["win_quality_sum"] > 0:
wqs = rec["win_quality_sum"] / wins
elif wins > 0:
wqs = 0.60 # default to decision-level
else:
wqs = 0.0
br = bonus_wins / wins if wins > 0 else 0.0
oss = (
rec["opp_winpct_sum"] / rec["opp_count"]
if rec["opp_count"] > 0
else 0.0
)
qls = (
rec["loss_quality_sum"] / rec["loss_count"]
if rec["loss_count"] > 0
else 0.0
)
# Recency Score: last 3 matches weighted double
rlist = sorted(
rec["results_by_date"],
key=lambda x: (pd.Timestamp.min if pd.isna(x[0]) else x[0]),
)
if rlist:
recent = rlist[-3:]
older = rlist[:-3]
recent_wins = sum(r for _, r in recent)
older_wins = sum(r for _, r in older)
recent_matches = len(recent)
older_matches = len(older)
rw, ow = 2, 1
denom = rw * recent_matches + ow * older_matches
if denom > 0:
rs = (rw * recent_wins + ow * older_wins) / denom
else:
rs = win_pct
else:
rs = win_pct
rows.append(
{
"Wrestler": name,
"Matches": m,
"Wins": wins,
"Losses": losses,
"WinPct": win_pct,
"WQS": wqs,
"BR": br,
"OSS": oss,
"QLS": qls,
"RS": rs,
}
)
rank_df = pd.DataFrame(rows)
if rank_df.empty:
return rank_df
# Optional filter: minimum matches
if MIN_MATCHES_FOR_RANKING > 0:
rank_df = rank_df[rank_df["Matches"] >= MIN_MATCHES_FOR_RANKING].copy()
if rank_df.empty:
return rank_df
# 6) Normalize metrics
rank_df["WQS_n"] = normalize(rank_df["WQS"])
rank_df["BR_n"] = normalize(rank_df["BR"])
rank_df["OSS_n"] = normalize(rank_df["OSS"])
rank_df["QLS_n"] = normalize(rank_df["QLS"])
rank_df["RS_n"] = normalize(rank_df["RS"])
# 7) Early-season composite score (model-only, no human yet)
rank_df["Score"] = (
0.25 * rank_df["WQS_n"]
+ 0.25 * rank_df["OSS_n"]
+ 0.15 * rank_df["BR_n"]
+ 0.15 * rank_df["QLS_n"]
+ 0.20 * rank_df["RS_n"]
)
# Keep a copy of pure-model score
rank_df["ScoreModel"] = rank_df["Score"]